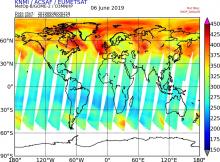
Mapping the global 3-dimensional distribution of ozone in the Earth's atmosphere
The goal of this project is to generate a consistent, homogeneous, and up to date vertical ozone profile data set. For studies of ozone, the global distribution and concentration of the trace gas must be known because of its role in various chemical reactions, and the absorption of UV radiation which drives many photolysis processes in the atmosphere. Large horizontal and vertical gradients in ozone concentration can exist in the atmosphere, which means that not only the horizontal distribution is needed, but also its vertical concentration profile. This profile of ozone can be derived from satellite instruments that measure back-scattered light in the UV spectral range. One example is the GOME-2 instrument on board of the polar orbiting Metop satellites.
By the end of December 2020, a new reprocessing of the spectral data (also called Level-1b data) from GOME-2 has become available. This new L1b dataset covers the period from the beginning of 2007 up to the end of 2018. It would be of great help to scientists in the ozone field to have a new consistent and homogeneous ozone profile dataset which is based on this new raw spectral data.
Supplier: Rackspace International GMBH - AWS
Olaf Tuinder
KNMI
Natural Sciences
Netherlands
Cloud Services
Processing hundreds of terabytes of data
Due to its complexity, the ozone profile retrieval is a relatively computationally expensive process and a reprocessing (i.e. re-calculating the complete back-catalog of data, usually with a new and better version of the algorithm) is done rarely due to the large computing resources needed. Satellite data is often quite large, and the data volume of this project is a few hundred of terabytes (the Level-1b input alone is estimated to be around 130TB). Regular workstations in the institute are just too small to handle this volume, so they need to look elsewhere.
The processing itself needed to be split up into several parts in a chain of tasks to come from the spectral input data to the ozone profile end product. Working in the cloud like this required careful planning and lots of testing. An important part of the discussion in the development stage of the project was what kind of resources to use in order to have an efficient workflow and low costs.
Once you turn on bulk processing it will go very fast if thousands of machines are running, but there is also the awareness that one little mistake would also waste a lot of resources just as fast.
Olaf Tuinder, KNMI
Infrastructure as a Service
The OCRE Cloud Funding for Research helped KNMI acquire experience with cloud computing for larger processing projects. It gave them the opportunity to try the Infrastructure as a Service (IaaS) computing resources in the AWS cloud (provided through OCRE Framework contract-holder Rackspace International GMBH), and do a relatively fast ozone profile retrieval reprocessing.
One thing that reduced their workflow speed in the beginning, was that the upload speed to the cloud was a limiting factor. The connection from the institute to the outside world was slower than the cloud could handle.
At this moment they have not yet completed the entire reprocessing (and have one more large calculation step to go) but hope to finish within a month (by June 2022).
Given that the cloud is pretty scalable in terms of compute resources, the tempo in which we could run through the calculation steps was much faster than we could have done with the limited resources at home.
Olaf Tuinder, KNMI
Speeding up computational tasks to let researchers do their job
Ultimately, this OCRE Cloud Funding helped KNMI to get the ozone profile reprocessing done faster so that the data could become available to downstream scientists sooner. This means that colleagues at KNMI and other scientists can do what they are good at, such as the validation of the ozone profile data.
The value of having an established, stable and homogeneous validated ozone profile data set is of relevance for international studies, such as the WMO 4-yearly Ozone Assessment report and the Tropospheric Ozone Assessment Report.
Contact us
Now that the OCRE Project has ended as of 31/12/2022, please contact GÉANT for any enquiries.